
Facebook?100种语言互译模型源代码公开!机器翻译

智东西(公众号:zhidxcom)
编 | 子佩
智东西10月23日消息,Facebook近期开源其M2M-100源代码,这是首个可以不依赖英语数据而可以实现100个语言对互相翻译的机器翻译模型(如中文-法文互译为一个语言对)。在训练2200种语言对后,该单一多语言模型不仅与传统的双语模型性能相当,同时也比以英语为中心的多语模型在机器翻译评价指标BLEU上提高了10%。
传统机器翻译算法通过为每种语言和每项任务构建单独的AI模型能够同时处理多语翻译,但由于依赖英语数据作为源语言和目标语言之间的中介,在语义准确性上可能有所折损。
为了实现多语言不依赖英语互译,研究人员使用不同的挖掘策略构建了首个真正的多对多翻译数据集,再通过Fairscale等扩展技术建立具有150亿个参数的通用翻译模型,使M2M-100可以从大量语言数据库中学习,并反映出更加多样化的语言文字和词法。
论文主页: src="https://p0.ssl.img.360kuai.com/t017e3e5d401c7b608e.jpg">一、多种技术融合,反向寻找海量数据
多语言机器翻译的目标是建立一个超7000种语言的一对一互译模型,如此大量级的模型需要大量数据来训练。由于小语种本身缺少可直接使用的大量数据,再加上如果要实现多语言间任意方向高质量翻译,例如中文到法语和法语到中文,模型训练所需要的数据量会随语言对数量呈二次增长。
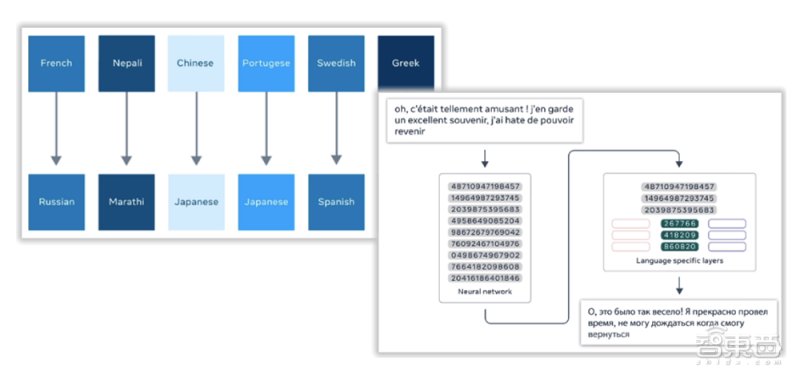
为此,Facebook在XLM-R,一种可以从单语数据中学习并以100种语言执行任务的模型上,增添了新颖的语言识别技术,用以从更多来源中挖掘更高质量的数据。如可以对自然语言处理模型进行零样本传输(one-shot transfer)的开放式源代码工具包Language-Agnostic Sentence Representations、用于训练翻译模型的“十亿规模” bitext数据集CCMatrix以及跨语言Web文档对的集合CCAligned。
除此之外,Facebook还使用反向翻译(back-translation)来补充数据较少的语料数据:如果目标是训练一个中文到法文的翻译模型,Facebook研究人员先训练一个法文到中文的模型,再将所有没被翻译的单语数据译成中文。在 M2M-100的开发过程中,反向翻译得到的数据会被添加到挖掘的并行数据中。
在得到的数据中,M2M-100也有三大筛选标准:被广泛使用的、不同语族的语言;已有评估标准数据的语言,以便更轻松地量化模型的性能;可以独立存在的语言。基于此,Facebook的M2M-100得到了100种不同语言超过75亿个句子的数据集。
“多年来,人工智能研究人员一直在努力构建一个单一的、跨语言的通用模型。”Facebook的数据科学家Angela Fan在博客中写道,“支持所有语言、方言的统一模型将帮助我们更好地为更多的人服务,并为数十亿人创造新的翻译体验。”
二、“桥接策略”构建语群,节约算力最大化但并不是100种语言对中任意一种都需要实现互译,例如冰岛语-尼泊尔语或僧伽罗语-爪哇语之间需要互译的情况是很少见的。Facebook研究人员为了避免这些少见的互译组合浪费算力,提出了“桥接策略”,即根据分类、地理和文化相似性将语言分为14个族。
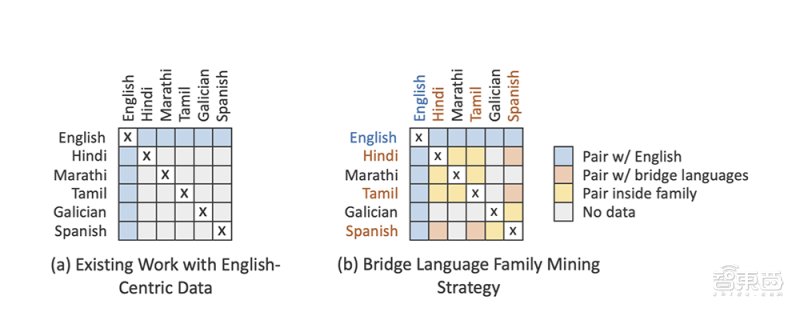
因为生活在相同语族的国家和地区的人们会更加频繁地交流,并从高质量的翻译中受益。例如,一个在印度地区生活的家庭可能日常会使用印度地区常用的语言,例如孟加拉语、北印度语、马拉地语、尼泊尔语、泰米尔语和乌尔都语等。
为了满足14个语群之间可能存在的互译需求,Facebook研究人员还确定了少数“过渡语言”,即每个语族中一到三种主要语言会作为桥梁转化不同语群语言。例如,印地语、孟加拉语和泰米尔语会成为印度-雅利雅语群中的桥梁语言。
研究人员会为桥梁语言的所有可能组合挖掘训练数据,从而获得上述数据集中的75亿个句子。
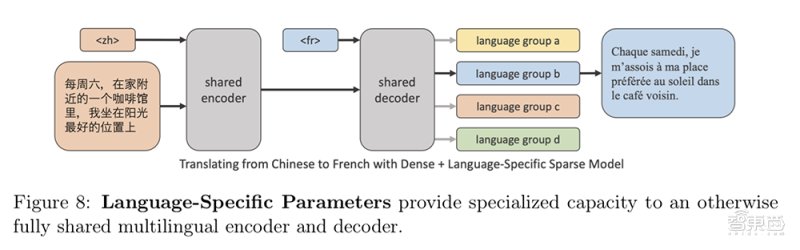
三、154亿参数,只为模型容量最优化在解决了如何获取数据和如何有效利用数据后,接下来的一步就是搭建模型。而在模型组建中遇见的最大问题就是:单一模型必须捕获多种不同语言的多种文字信息,这时候就需要扩展模型的容量及添加特定语言参数用以处理更多语言数据。
M2M-100借助了Fairscale(一种用于大型模型训练的PyTorch库),来增加Transformer网络中的层数以及每层的宽度。基于Zero优化器、层内模型并行性和管道模型并行性,研究人员建立通用的基础架构来容纳无法在单个GPU安装的大型模型,此外还引入了模型压缩和深度自适应模型,以用常规主干和一些语言特定参数集来共同训练模型。
上一篇:县语言艺术协会举办“朗诵技巧”公益讲座
下一篇:没有了




